
10分钟大数据Hadoop基础入门「值得收藏」
bigegpt 2025-01-29 14:27 9 浏览
前言
目前人工智能和大数据火热,使用的场景也越来越广,日常开发中前端同学也逐渐接触了更多与大数据相关的开发需求。因此对大数据知识也有必要进行一些学习理解。
基础概念
大数据的本质
一、数据的存储:分布式文件系统(分布式存储)
二、数据的计算:分部署计算
基础知识
学习大数据需要具备Java知识基础及Linux知识基础
学习路线
(1)Java基础和Linux基础
(2)Hadoop的学习:体系结构、原理、编程
第一阶段:HDFS、MapReduce、HBase(NoSQL数据库)
第二阶段:数据分析引擎 -> Hive、Pig
数据采集引擎 -> Sqoop、Flume
第三阶段:HUE:Web管理工具
ZooKeeper:实现Hadoop的HA Oozie:工作流引擎
(3)Spark的学习
第一阶段:Scala编程语言 第二阶段:Spark Core -> 基于内存、数据的计算 第三阶段:Spark SQL -> 类似于mysql 的sql语句 第四阶段:Spark Streaming ->进行流式计算:比如:自来水厂
(4)Apache Storm 类似:Spark Streaming ->进行流式计算
NoSQL:Redis基于内存的数据库
HDFS
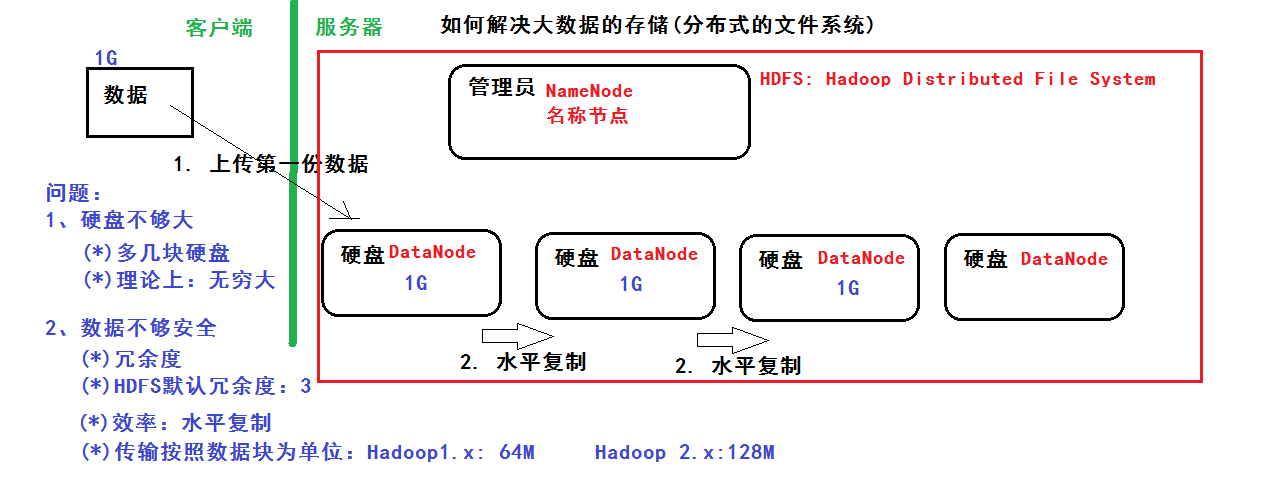
分布式文件系统 解决以下问题:
1、硬盘不够大:多几块硬盘,理论上可以无限大 2、数据不够安全:冗余度,hdfs默认冗余为3 ,用水平复制提高效率,传输按照数据库为单位:Hadoop1.x 64M,Hadoop2.x 128M
管理员:NameNode 硬盘:DataNode
MapReduce
基础编程模型:把一个大任务拆分成小任务,再进行汇总 MR任务:Job = Map + Reduce Map的输出是Reduce的输入、MR的输入和输出都是在HDFS
MapReduce数据流程分析:
Map的输出是Reduce的输入,Reduce的输入是Map的集合
HBase
什么是BigTable?: 把所有的数据保存到一张表中,采用冗余 ---> 好处:提高效率
1、因为有了bigtable的思想:NoSQL:HBase数据库 2、HBase基于Hadoop的HDFS的 3、描述HBase的表结构 核心思想是:利用空间换效率
Hadoop环境搭建
环境准备
Linux环境、JDK、http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-3.0.0/hadoop-3.0.0-src.tar.gz
安装
1、安装jdk、并配置环境变量
vim /etc/profile 末尾添加 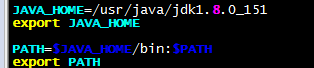
2、解压hadoop-3.0.0.tar.gz、并配置环境变量
tar -zxvf hadoop-3.0.0.tar.gz -C /usr/local/ mv hadoop-3.0.0/ hadoop
vim /etc/profile 末尾添加
配置
Hadoop有三种安装模式:
本地模式: 1台主机 不具备HDFS,只能测试MapReduce程序 伪分布模式: 1台主机 具备Hadoop的所有功能,在单机上模拟一个分布式的环境 (1)HDFS:主:NameNode,数据节点:DataNode (2)Yarn:容器,运行MapReduce程序 主节点:ResourceManager 从节点:NodeManager 全分布模式: 至少3台
我们以伪分布模式为例配置:
修改hdfs-site.xml:冗余度1、权限检查false
<!--配置冗余度为1--><property> <name>dfs.replication</name> <value>1</value></property><!--配置权限检查为false--><property> <name>dfs.permissions</name> <value>false</value></property>
修改core-site.xml
<!--配置HDFS的NameNode--><property> <name>fs.defaultFS</name> <value>hdfs://192.168.56.102:9000</value></property><!--配置DataNode保存数据的位置--><property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value></property>
修改mapred-site.xml
<!--配置MR运行的框架--><property> <name>mapreduce.framework.name</name> <value>yar</value></property><property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property><property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property><property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property><property> <name>mapreduce.application.classpath</name> <value> /usr/local/hadoop/etc/hadoop, /usr/local/hadoop/share/hadoop/common/*, /usr/local/hadoop/share/hadoop/common/lib/*, /usr/local/hadoop/share/hadoop/hdfs/*, /usr/local/hadoop/share/hadoop/hdfs/lib/*, /usr/local/hadoop/share/hadoop/mapreduce/*, /usr/local/hadoop/share/hadoop/mapreduce/lib/*, /usr/local/hadoop/share/hadoop/yarn/*, /usr/local/hadoop/share/hadoop/yarn/lib/*, </value> </property>
修改yarn-site.xml
<!--配置ResourceManager地址--><property> <name>yarn.resourcemanager.hostname</name> <value>192.168.56.102</value></property><!--配置NodeManager执行任务的方式--><property> <name>yarn.nodemanager.aux-service</name> <value>mapreduce_shuffle</value></property>
格式化NameNode
hdfs namenode -format
看到
common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted
表示格式化成功
启动
start-all.sh
(*)HDFS:存储数据
(*)YARN:
访问
(*)命令行
(*)Java Api
(*)WEB Console
HDFS: http://192.168.56.102:50070
Yarn: http://192.168.56.102:8088
查看HDFS管理界面和yarn资源管理系统
基本操作:
HDFS相关命令
-mkdir 在HDFD创建目录 hdfs dfs -mkdir /data -ls 查看目录 hdfs dfs -ls -ls -R 查看目录与子目录 hdfs dfs -ls -R -put 上传一个文件 hdfs dfs -put data.txt /data/input -copyFromLocal 上传一个文件 与-put一样 -moveFromLocal 上传一个文件并删除本地文件 -copyToLocal 下载文件 hdfs dfs -copyTolocal /data/input/data.txt -put 下载文件 hdfs dfs -put/data/input/data.txt -rm 删除文件 hdfs dfs -rm -getmerge 将目录所有文件先合并再下载 -cp 拷贝 -mv 移动 -count 统计目录下的文件个数 -text、-cat 查看文件 -balancer 平衡操作
MapReduce示例
结果:
如上 一个最简单的MapReduce示例就执行成功了
思考
Hadoop是基于Java语言的,前端日常开发是用的PHP,在使用、查找错误时还是蛮吃力的。工作之余还是需要多补充点其它语言的相关知识,编程语言是我们开发、学习的工具,而不应成为限制我们技术成长的瓶颈!
大数据开发高薪必备全套资源【免费获取】
Oracle高级技术总监多年精心创作一套完整课程体系【大数据、人工智能开发必看】,全面助力大数据开发零基础+入门+提升+项目=高薪!
「大数据零基础入门」
「大数据架构系统组件」
「大数据全套系统工具安装包」
Java必备工具
大数据必备工具
「大数据行业必备知资讯」
「大数据精品实战案例」
「大数据就业指导方案」
最后说一下的,也就是以上教程的获取方式!
领取方法:
还是那个万年不变的老规矩
1.评论文章,没字数限制,一个字都行!
2.成为小编成为的粉丝!
3.私信小编:“大数据开发教程”即可!
谢谢大家,祝大家学习愉快!(拿到教程后一定要好好学习,多练习哦!)
相关推荐
- 当Frida来“敲”门(frida是什么)
-
0x1渗透测试瓶颈目前,碰到越来越多的大客户都会将核心资产业务集中在统一的APP上,或者对自己比较重要的APP,如自己的主业务,办公APP进行加壳,流量加密,投入了很多精力在移动端的防护上。而现在挖...
- 服务端性能测试实战3-性能测试脚本开发
-
前言在前面的两篇文章中,我们分别介绍了性能测试的理论知识以及性能测试计划制定,本篇文章将重点介绍性能测试脚本开发。脚本开发将分为两个阶段:阶段一:了解各个接口的入参、出参,使用Python代码模拟前端...
- Springboot整合Apache Ftpserver拓展功能及业务讲解(三)
-
今日分享每天分享技术实战干货,技术在于积累和收藏,希望可以帮助到您,同时也希望获得您的支持和关注。架构开源地址:https://gitee.com/msxyspringboot整合Ftpserver参...
- Linux和Windows下:Python Crypto模块安装方式区别
-
一、Linux环境下:fromCrypto.SignatureimportPKCS1_v1_5如果导包报错:ImportError:Nomodulenamed'Crypt...
- Python 3 加密简介(python des加密解密)
-
Python3的标准库中是没多少用来解决加密的,不过却有用于处理哈希的库。在这里我们会对其进行一个简单的介绍,但重点会放在两个第三方的软件包:PyCrypto和cryptography上,我...
- 怎样从零开始编译一个魔兽世界开源服务端Windows
-
第二章:编译和安装我是艾西,上期我们讲述到编译一个魔兽世界开源服务端环境准备,那么今天跟大家聊聊怎么编译和安装我们直接进入正题(上一章没有看到的小伙伴可以点我主页查看)编译服务端:在D盘新建一个文件夹...
- 附1-Conda部署安装及基本使用(conda安装教程)
-
Windows环境安装安装介质下载下载地址:https://www.anaconda.com/products/individual安装Anaconda安装时,选择自定义安装,选择自定义安装路径:配置...
- 如何配置全世界最小的 MySQL 服务器
-
配置全世界最小的MySQL服务器——如何在一块IntelEdison为控制板上安装一个MySQL服务器。介绍在我最近的一篇博文中,物联网,消息以及MySQL,我展示了如果Partic...
- 如何使用Github Action来自动化编译PolarDB-PG数据库
-
随着PolarDB在国产数据库领域荣膺桂冠并持续获得广泛认可,越来越多的学生和技术爱好者开始关注并涉足这款由阿里巴巴集团倾力打造且性能卓越的关系型云原生数据库。有很多同学想要上手尝试,却卡在了编译数据...
- 面向NDK开发者的Android 7.0变更(ndk android.mk)
-
订阅Google官方微信公众号:谷歌开发者。与谷歌一起创造未来!受Android平台其他改进的影响,为了方便加载本机代码,AndroidM和N中的动态链接器对编写整洁且跨平台兼容的本机...
- 信创改造--人大金仓(Kingbase)数据库安装、备份恢复的问题纪要
-
问题一:在安装KingbaseES时,安装用户对于安装路径需有“读”、“写”、“执行”的权限。在Linux系统中,需要以非root用户执行安装程序,且该用户要有标准的home目录,您可...
- OpenSSH 安全漏洞,修补操作一手掌握
-
1.漏洞概述近日,国家信息安全漏洞库(CNNVD)收到关于OpenSSH安全漏洞(CNNVD-202407-017、CVE-2024-6387)情况的报送。攻击者可以利用该漏洞在无需认证的情况下,通...
- Linux:lsof命令详解(linux lsof命令详解)
-
介绍欢迎来到这篇博客。在这篇博客中,我们将学习Unix/Linux系统上的lsof命令行工具。命令行工具是您使用CLI(命令行界面)而不是GUI(图形用户界面)运行的程序或工具。lsoflsof代表&...
- 幻隐说固态第一期:固态硬盘接口类别
-
前排声明所有信息来源于网络收集,如有错误请评论区指出更正。废话不多说,目前固态硬盘接口按速度由慢到快分有这几类:SATA、mSATA、SATAExpress、PCI-E、m.2、u.2。下面我们来...
- 新品轰炸 影驰SSD多款产品登Computex
-
分享泡泡网SSD固态硬盘频道6月6日台北电脑展作为全球第二、亚洲最大的3C/IT产业链专业展,吸引了众多IT厂商和全球各地媒体的热烈关注,全球存储新势力—影驰,也积极参与其中,为广大玩家朋友带来了...
- 一周热门

- 最近发表
-
- 当Frida来“敲”门(frida是什么)
- 服务端性能测试实战3-性能测试脚本开发
- Springboot整合Apache Ftpserver拓展功能及业务讲解(三)
- Linux和Windows下:Python Crypto模块安装方式区别
- Python 3 加密简介(python des加密解密)
- 怎样从零开始编译一个魔兽世界开源服务端Windows
- 附1-Conda部署安装及基本使用(conda安装教程)
- 如何配置全世界最小的 MySQL 服务器
- 如何使用Github Action来自动化编译PolarDB-PG数据库
- 面向NDK开发者的Android 7.0变更(ndk android.mk)
- 标签列表
-
- mybatiscollection (79)
- mqtt服务器 (88)
- keyerror (78)
- c#map (65)
- resize函数 (64)
- xftp6 (83)
- bt搜索 (75)
- c#var (76)
- mybatis大于等于 (64)
- xcode-select (66)
- mysql授权 (74)
- 下载测试 (70)
- linuxlink (65)
- pythonwget (67)
- androidinclude (65)
- libcrypto.so (74)
- logstashinput (65)
- hadoop端口 (65)
- vue阻止冒泡 (67)
- jquery跨域 (68)
- php写入文件 (73)
- kafkatools (66)
- mysql导出数据库 (66)
- jquery鼠标移入移出 (71)
- 取小数点后两位的函数 (73)